
28 Sep
2019
28 Sep
'19
3:28 p.m.
Hi
I have noted that the normalisation applied in the demo notebook here:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
Does not apply the same normalisation as the code here:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
Specifically, delay is not normalised in the demo notebook.
The demo notebook loads a checkpoint from here:
https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/tra…
<https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/trained_models>
This model, then, was created without normalising the delay also. That implies that the
code that was used to train that model is not the same code that is in the
routenet_with_link_cap.py code at the link above.
In simpler terms, the demo notebook prediction does not work if the delay is normalised as
at routenet_with_link_cap.py#L85. So, the code for training given in this repository is
not compatible with the demo notebook and the trained model used as an example.
Regards
Nathan

30 Sep
30 Sep
10:13 a.m.
Hi Nathan,
The code in the demo notebook is used only for delay inference, not for
training. In this code, we load a model that we trained using the
RouteNet implementation in "routenet_with_link_cap.py". Then, we load
samples from our datasets (generated with our packet-level simulator),
make the inference with the RouteNet model and finally compare
RouteNet's predictions with the values of our ground truth.
In this case it is not necessary to normalize the output parameters
(i.e., delay) since we are not using them for training. We only
normalize the input parameters of RouteNet (traffic and link
capacities). Note that we then denormalize RouteNet's predictions to
compare them with the real (denormalized) delay values of the ground
truth (variable "label_Delay"):
predictions = 0.54*preds + 0.37
Regards,
José
El 28/09/19 a las 17:28, Nathan Sowatskey escribió:
Hi
I have noted that the normalisation applied in the demo notebook here:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
Does not apply the same normalisation as the code here:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
Specifically, delay is not normalised in the demo notebook.
The demo notebook loads a checkpoint from here:
https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/tra…
This model, then, was created without normalising the delay also. That
implies that the code that was used to train that model is not the
same code that is in the routenet_with_link_cap.py code at the link above.
In simpler terms, the demo notebook prediction does not work if the
delay is normalised as at routenet_with_link_cap.py#L85. So, the code
for training given in this repository is not compatible with the demo
notebook and the trained model used as an example.
Regards
Nathan
_______________________________________________
Kdn-users mailing list
Kdn-users(a)knowledgedefinednetworking.org
https://mail.n3cat.upc.edu/cgi-bin/mailman/listinfo/kdn-users
6 Oct
6 Oct
7:55 a.m.
Thank you José.
I am trying to make sense of this, so I appreciate you bearing with me. The normalisation
seems to be fundamental to how RouteNet is used, but also seems not to be discussed
anywhere, so I just have the clues in the code to work with.
In my experiments, I have performed the training with the delay input normalised, and not
normalised.
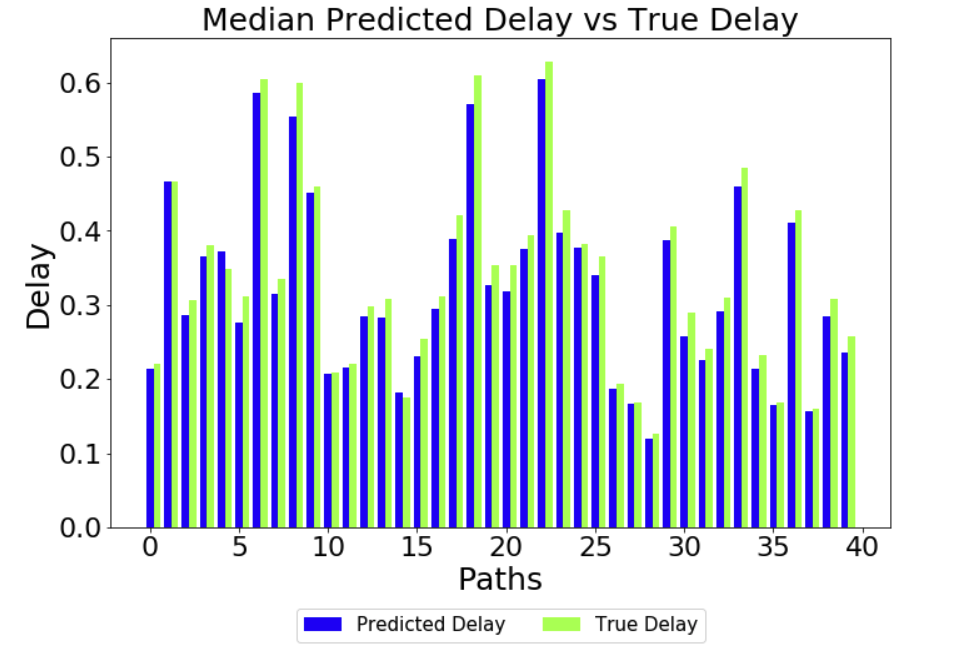
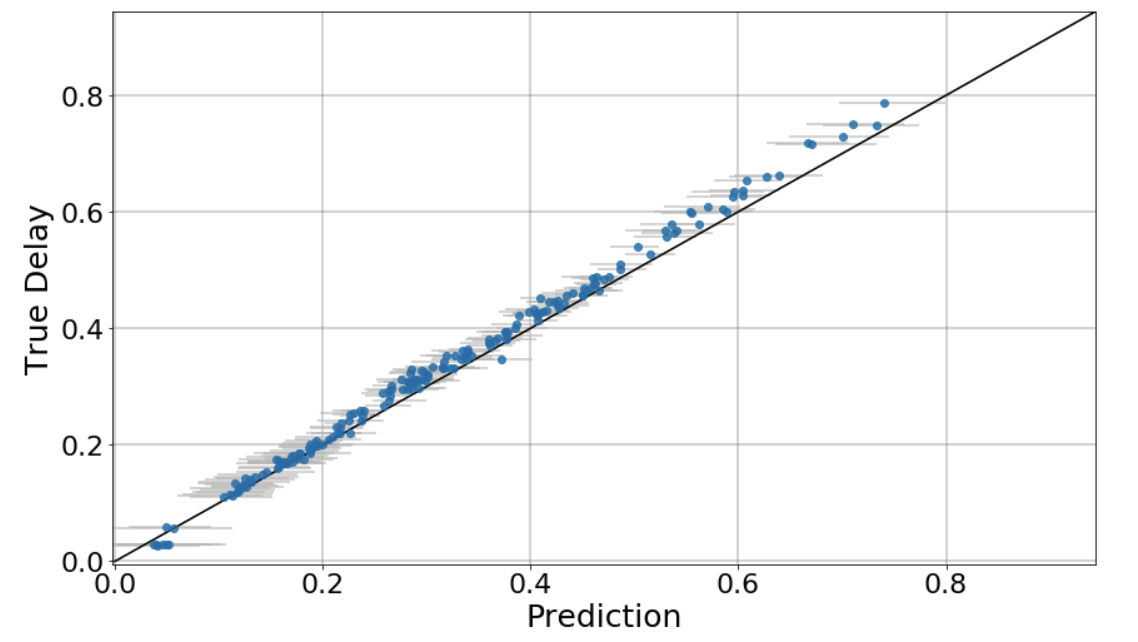
Predictions with Delay Normalised as an Input Variable
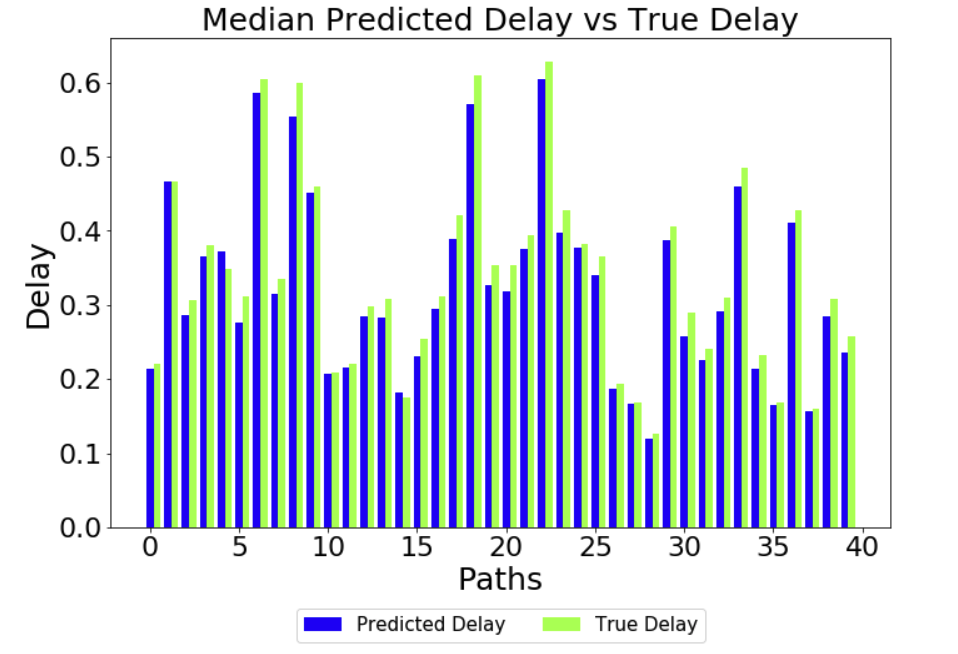
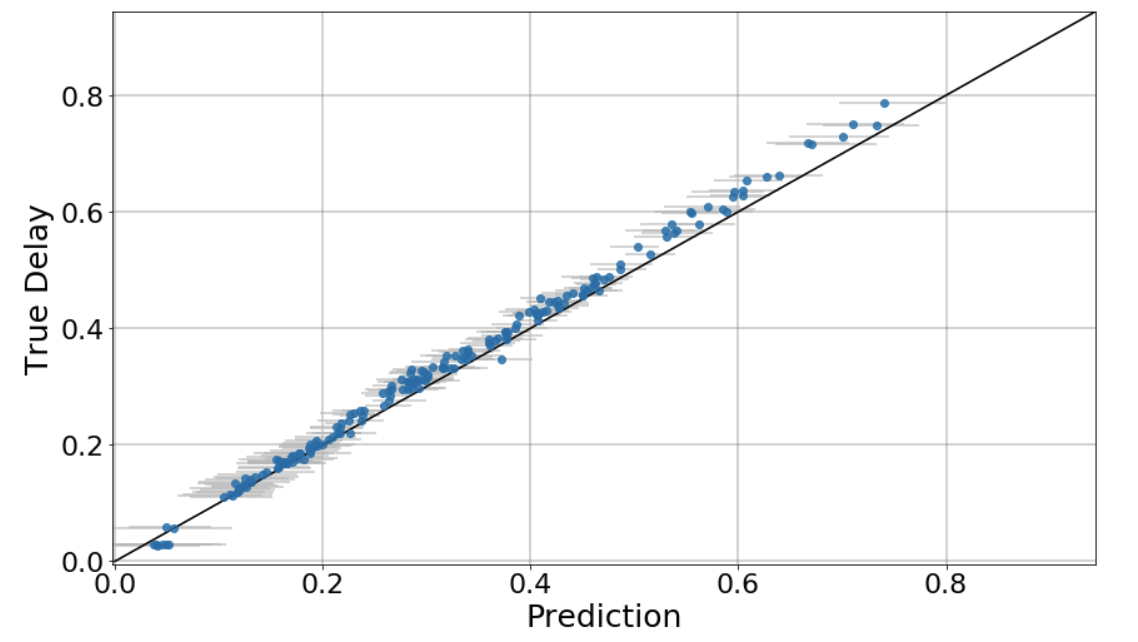
-------------------------------------------------------------------------
If I normalise the delay input value, and (de)normalise the predictions, I get results
like this (this is with a checkpoint 51211).
Looking at these results, one could draw the conclusion that the end-to-end process is
working as expected. What is not explained, though, is the reasoning behind the
normalisation.
You do say in your response below, though, that “it is not necessary to normalise the
output parameters (i.e., delay) since we are not using them for training”, which seems
perfectly sensible. Given this, common sense, point, I don’t understand why the delay is
normalised in the parse function here:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
That parse function is used when reading the TF records data and passing it to the model
during training. So, transforming the delay value at that point doesn’t make sense given
that we are not using it for prediction.
Since the demo notebook does also (de)normalise the predictions, it seems as though the
trained model in the supplied checkpoint 260380 actually was trained with the delay value
normalised, and so it had to be (de)normalised in the notebook, which is the result I have
reproduced here.
There is no explicit rationale provided for normalising the target variable, or the other
input variables, though. If this is required here, then it might be for scaling purposes.
If that is the case, then I would suppose that there is some analysis that you have done
to determine the appropriate scaling factors. If that analysis does exist, it might have
been published somewhere I have not found yet.
What might, also, make sense is if the delay is normalised when the code is being used
with jitter as the prediction target, but the code seems to be all about delay at this
stage.
As I note above, since the normalisation appears not to be discussed anywhere, I only have
the clues in the code to go on.
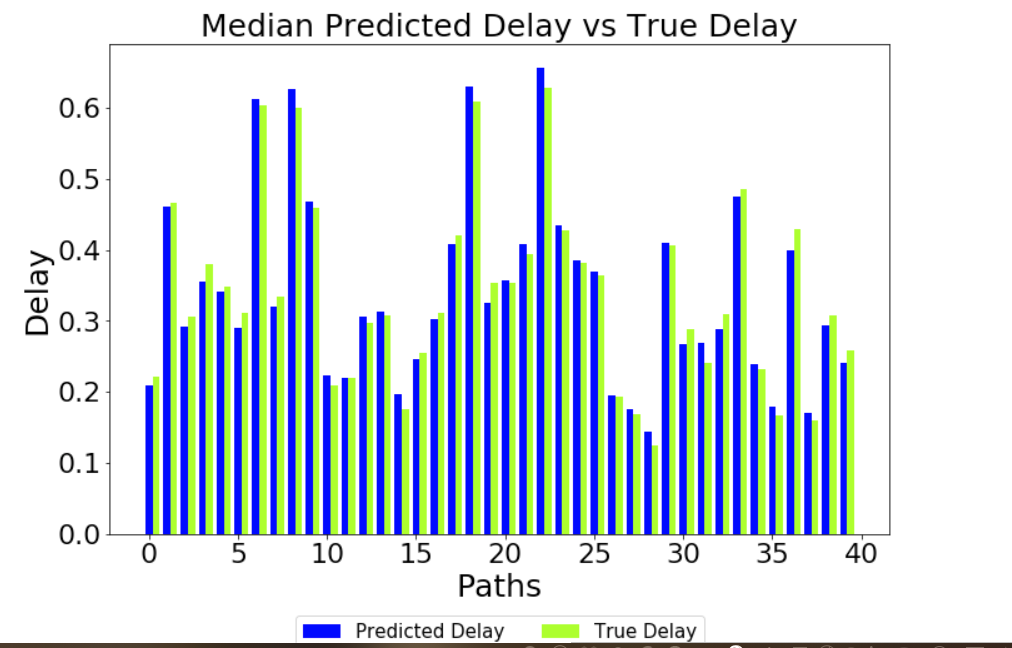
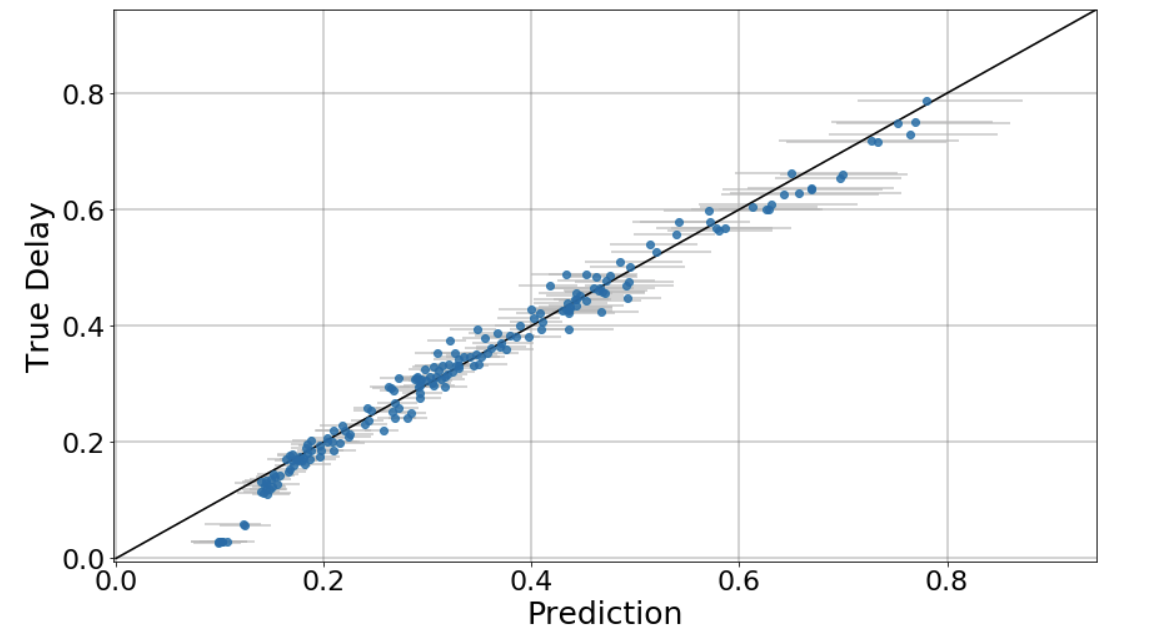
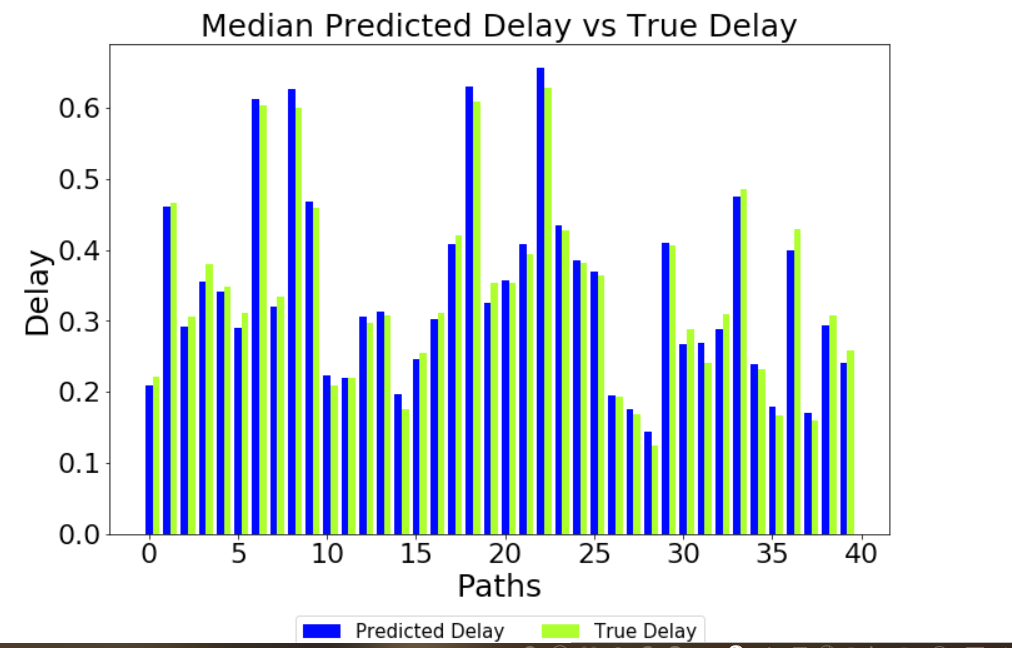
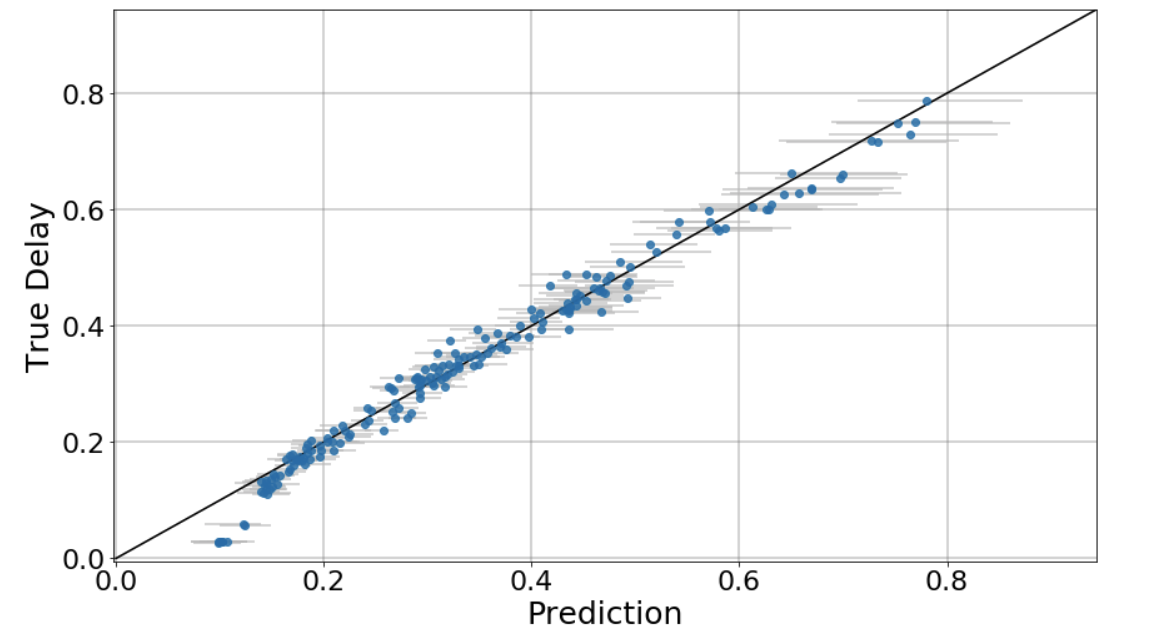
Predictions without Delay Normalised as an Input Variable
-----------------------------------------------------------------------------
For comparison, I have also trained without the delay value normalised, but with the
traffic and link_capacity normalised, as below in the parse function:
if feature == 'traffic':
features[feature] = (features[feature] - 0.17) / 0.13
if feature == 'link_capacity':
features[feature] = (features[feature] - 25.0) / 40.0
I also do not normalise the predictions, and I get results like this from a checkpoint
5904 (which is to say an early stage in the training):
Given these results, it looks like the model I am training, without normalising delay
either as an input variable, or denormalising the delay predictions, is providing
reasonable predictions (given that it has only been trained for a relatively small number
of training steps).
Conclusion
---------------
A possible conclusion is simply that I have broken something in the way in which I have
refactored your original code. You will see, though, that I have been careful to also
write extensive unit and smoke tests, so I have confidence that my refactoring has not
changed the original functions of the code.
My code, though, seems to produce reasonable predictions for delay without normalisation
of the delay. Of course, I am still using your original normalisation for the traffic and
link capacity, without understanding why yet.
What are your thoughts please? Has the normalisation that you are employing been discussed
anywhere?
Many thanks
Nathan
On 30 Sep 2019, at 12:13, José Suárez-Varela
<jsuarezv(a)ac.upc.edu> wrote:
Hi Nathan,
The code in the demo notebook is used only for delay inference, not for training. In this
code, we load a model that we trained using the RouteNet implementation in
"routenet_with_link_cap.py". Then, we load samples from our datasets (generated
with our packet-level simulator), make the inference with the RouteNet model and finally
compare RouteNet's predictions with the values of our ground truth.
In this case it is not necessary to normalize the output parameters (i.e., delay) since
we are not using them for training. We only normalize the input parameters of RouteNet
(traffic and link capacities). Note that we then denormalize RouteNet's predictions to
compare them with the real (denormalized) delay values of the ground truth (variable
"label_Delay"):
predictions = 0.54*preds + 0.37
Regards,
José
El 28/09/19 a las 17:28, Nathan Sowatskey escribió:
> Hi
>
> I have noted that the normalisation applied in the demo notebook here:
>
>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
>
> Does not apply the same normalisation as the code here:
>
>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
>
> Specifically, delay is not normalised in the demo notebook.
>
> The demo notebook loads a checkpoint from here:
>
>
https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/tra…
>
> This model, then, was created without normalising the delay also. That implies that
the code that was used to train that model is not the same code that is in the
routenet_with_link_cap.py code at the link above.
>
> In simpler terms, the demo notebook prediction does not work if the delay is
normalised as at routenet_with_link_cap.py#L85. So, the code for training given in this
repository is not compatible with the demo notebook and the trained model used as an
example.
>
> Regards
>
> Nathan
>
>
> _______________________________________________
> Kdn-users mailing list
>
> Kdn-users(a)knowledgedefinednetworking.org
> https://mail.n3cat.upc.edu/cgi-bin/mailman/listinfo/kdn-users
{kind=link}
{kind=link}
{kind=link}
{kind=link}
8 Oct
8 Oct
3:54 p.m.
Hi Nathan,
Normalizing the input and output values is a well-known technique to
provide training stability to Deep Learning models in general. Usually,
if the input and output variables of the model follow a normal
distribution [N(0,1)], it is easier for deep learning models to learn
the data. This does not necessarily mean that the model won't work if
you don't normalize the data, but it often facilitates the loss of the
model to converge during training. You can see this as an optimization
technique. A common approach is just to measure the mean and standard
deviation on your training dataset (or a representative subset) and
normalize individually each variable by applying a linear transformation
[i.e., (x - mean)/std. dev.]. This is what we did in the ACM SOSR paper.
However, another approach that we experimentally tried is to select the
normalization function based on the value distribution of each variable.
Then, in the case of RouteNet with nodes
(https://github.com/knowledgedefinednetworking/network-modeling-GNN/blob/mas…)
we analyzed the distribution of delays in our training dataset (not
public yet) and given that the distribution had a lot of density for low
values and a long tail for large values we thought that using a
logarithmic function to normalize could be more beneficial (and it was
eventually) to make the delay distribution seen by RouteNet closer to a
normal distribution.
Note that the parse function in our code reads the data from the dataset
(tfrecords). Then, when you normalize the delay labels
(features['delay']) it means that you take the delay values from the
ground truth (obtained by our packet-level simulator) and normalize
them. To train RouteNet we need supervised data (with labels), then we
normalize the labels from the ground truth (features['delay']) and use
them to train the model.
Once RouteNet is trained you can use it to produce predictions. In this
case the model is fed only by inputs (i.e., traffic, topology, routing)
and it produces an output value. If it was trained with normalized
output labels, it will produce normalized outputs and it is necessary to
apply denormalization to get the real values. In principle, during
evaluation you can ignore the delay values (features['delay']) in the
parse function given that they are the labels used for training (i.e.,
the output of our simulator).
Regarding the code in the following link:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
The parse function was used to train the RouteNet model. In this case we
normalized the data before we introduced it to RouteNet. It means that,
once the model is trained, we need to denormalize the output delay
values of RouteNet to obtain the actual delay predictions. Then, in our
demo notebook
(https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…)
we loaded a model already trained. Note that to make predictions with
RouteNet, the training delay labels (features['delay']) are not needed
anymore. However, in this demo we wanted to compare the predictions made
by RouteNet (after denormalization) with the values produced by our
simulator in a separate dataset that wasn't used for the training. Then,
we retrieve the actual delay values of the simulator (features['delay'])
without denormalization. Also, since we normalized the output labels of
RouteNet during training (in the function parse in
"routenet_with_link_cap.py"), we need to apply the reverse function to
denormalize the delays:
_Training_ ("demo-routenet/code/routenet_with_link_cap.py"):
parse function:
if k == 'delay':
features[k] = (features[k] - 0.37) / 0.54 --> Delay
labels normalized used to train RouteNet
_Evaluation_ ("demo-routenet/demo_notebooks/demo.ipynb"):
pred_Delay, label_Delay = sess.run([predictions, label])
"label" --> Real values produced by the simulator (label =
features[target] = features['delay'])
predictions = 0.54*preds + 0.37 --> Denormalization applied to RouteNet
predictions during the evaluation phase to obtain the real delay values
predicted. Note that this is the reverse function of the one applied in
the training (function parse in
"demo-routenet/code/routenet_with_link_cap.py").
I hope this will clarify all your doubts.
Regards,
José
El 6/10/19 a las 09:55, Nathan Sowatskey escribió:
Thank you José.
I am trying to make sense of this, so I appreciate you bearing with
me. The normalisation seems to be fundamental to how RouteNet is used,
but also seems not to be discussed anywhere, so I just have the clues
in the code to work with.
In my experiments, I have performed the training with the delay input
normalised, and not normalised.
Predictions with Delay Normalised as an Input Variable
-------------------------------------------------------------------------
If I normalise the delay input value, and (de)normalise the
predictions, I get results like this (this is with a checkpoint 51211).
Looking at these results, one could draw the conclusion that the
end-to-end process is working as expected. What is not explained,
though, is the reasoning behind the normalisation.
You do say in your response below, though, that “it is not necessary
to normalise the output parameters (i.e., delay) since we are not
using them for training”, which seems perfectly sensible. Given this,
common sense, point, I don’t understand why the delay is normalised in
the parse function here:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
That parse function is used when reading the TF records data and
passing it to the model during training. So, transforming the delay
value at that point doesn’t make sense given that we are not using it
for prediction.
Since the demo notebook does also (de)normalise the predictions, it
seems as though the trained model in the supplied checkpoint 260380
actually was trained with the delay value normalised, and so it had to
be (de)normalised in the notebook, which is the result I have
reproduced here.
There is no explicit rationale provided for normalising the target
variable, or the other input variables, though. If this is required
here, then it might be for scaling purposes. If that is the case, then
I would suppose that there is some analysis that you have done to
determine the appropriate scaling factors. If that analysis does
exist, it might have been published somewhere I have not found yet.
What might, also, make sense is if the delay is normalised when the
code is being used with jitter as the prediction target, but the code
seems to be all about delay at this stage.
As I note above, since the normalisation appears not to be discussed
anywhere, I only have the clues in the code to go on.
Predictions without Delay Normalised as an Input Variable
-----------------------------------------------------------------------------
For comparison, I have also trained without the delay value
normalised, but with the traffic and link_capacity normalised, as
below in the parse function:
if feature == 'traffic':
features[feature] = (features[feature] - 0.17) / 0.13
if feature == 'link_capacity':
features[feature] = (features[feature] - 25.0) / 40.0
I also do not normalise the predictions, and I get results like this
from a checkpoint 5904 (which is to say an early stage in the training):
Given these results, it looks like the model I am training, without
normalising delay either as an input variable, or denormalising the
delay predictions, is providing reasonable predictions (given that it
has only been trained for a relatively small number of training steps).
Conclusion
---------------
A possible conclusion is simply that I have broken something in the
way in which I have refactored your original code. You will see,
though, that I have been careful to also write extensive unit and
smoke tests, so I have confidence that my refactoring has not changed
the original functions of the code.
My code, though, seems to produce reasonable predictions for delay
without normalisation of the delay. Of course, I am still using your
original normalisation for the traffic and link capacity, without
understanding why yet.
What are your thoughts please? Has the normalisation that you are
employing been discussed anywhere?
Many thanks
Nathan
> On 30 Sep 2019, at 12:13, José Suárez-Varela <jsuarezv(a)ac.upc.edu
> <mailto:jsuarezv@ac.upc.edu>> wrote:
>
>
> Hi Nathan,
>
> The code in the demo notebook is used only for delay inference, not
> for training. In this code, we load a model that we trained using the
> RouteNet implementation in "routenet_with_link_cap.py". Then, we load
> samples from our datasets (generated with our packet-level
> simulator), make the inference with the RouteNet model and finally
> compare RouteNet's predictions with the values of our ground truth.
>
> In this case it is not necessary to normalize the output parameters
> (i.e., delay) since we are not using them for training. We only
> normalize the input parameters of RouteNet (traffic and link
> capacities). Note that we then denormalize RouteNet's predictions to
> compare them with the real (denormalized) delay values of the ground
> truth (variable "label_Delay"):
>
> predictions = 0.54*preds + 0.37
>
>
>
> Regards,
>
> José
>
> El 28/09/19 a las 17:28, Nathan Sowatskey escribió:
>> Hi
>>
>> I have noted that the normalisation applied in the demo notebook here:
>>
>>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
>>
>> Does not apply the same normalisation as the code here:
>>
>>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
>>
>> Specifically, delay is not normalised in the demo notebook.
>>
>> The demo notebook loads a checkpoint from here:
>>
>>
https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/tra…
>>
>> This model, then, was created without normalising the delay also.
>> That implies that the code that was used to train that model is not
>> the same code that is in the routenet_with_link_cap.py code at
>> the link above.
>>
>> In simpler terms, the demo notebook prediction does not work if the
>> delay is normalised as at routenet_with_link_cap.py#L85. So, the
>> code for training given in this repository is not compatible with
>> the demo notebook and the trained model used as an example.
>>
>> Regards
>>
>> Nathan
>>
>>
>> _______________________________________________
>> Kdn-users mailing list
>>
>> Kdn-users(a)knowledgedefinednetworking.org
>> https://mail.n3cat.upc.edu/cgi-bin/mailman/listinfo/kdn-users
{kind=link}
{kind=link}
{kind=link}
{kind=link}
9 Oct
9 Oct
4:52 a.m.
Many thanks.
I presume that the [(x - mean)/std. dev] is also the basis of the normalisation for
traffic and link_capacity, is that right?
In general, I should be introducing a function that carries out this same normalisation
analysis for any given data set, as the actual values for mean and standard deviation will
differ from one training data set to another for different domains.
Presumably, also, you will have been thinking about being able to label a given trained
model with the characteristics of the data it has been trained with, such that, given a
range of trained models, you could choose the appropriate trained model given the
characteristics of the data you are predicting from.
I imagine (and I can test later), that the OMNet++ generated data sets that you used
originally all have similar characteristics.
Regards
Nathan
On 8 Oct 2019, at 16:54, José Suárez-Varela
<jsuarezv(a)ac.upc.edu> wrote:
Hi Nathan,
Normalizing the input and output values is a well-known technique to provide training
stability to Deep Learning models in general. Usually, if the input and output variables
of the model follow a normal distribution [N(0,1)], it is easier for deep learning models
to learn the data. This does not necessarily mean that the model won't work if you
don't normalize the data, but it often facilitates the loss of the model to converge
during training. You can see this as an optimization technique. A common approach is just
to measure the mean and standard deviation on your training dataset (or a representative
subset) and normalize individually each variable by applying a linear transformation
[i.e., (x - mean)/std. dev.]. This is what we did in the ACM SOSR paper. However, another
approach that we experimentally tried is to select the normalization function based on the
value distribution of each variable. Then, in the case of RouteNet with nodes
(https://github.com/knowledgedefinednetworking/network-modeling-GNN/blob/mas…
<https://github.com/knowledgedefinednetworking/network-modeling-GNN/blob/master/routenet_with_forwarding_nodes/routenet_with_forwarding_nodes.py>)
we analyzed the distribution of delays in our training dataset (not public yet) and given
that the distribution had a lot of density for low values and a long tail for large values
we thought that using a logarithmic function to normalize could be more beneficial (and it
was eventually) to make the delay distribution seen by RouteNet closer to a normal
distribution.
Note that the parse function in our code reads the data from the dataset (tfrecords).
Then, when you normalize the delay labels (features['delay']) it means that you
take the delay values from the ground truth (obtained by our packet-level simulator) and
normalize them. To train RouteNet we need supervised data (with labels), then we normalize
the labels from the ground truth (features['delay']) and use them to train the
model.
Once RouteNet is trained you can use it to produce predictions. In this case the model is
fed only by inputs (i.e., traffic, topology, routing) and it produces an output value. If
it was trained with normalized output labels, it will produce normalized outputs and it is
necessary to apply denormalization to get the real values. In principle, during evaluation
you can ignore the delay values (features['delay']) in the parse function given
that they are the labels used for training (i.e., the output of our simulator).
Regarding the code in the following link:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
<https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/code/routenet_with_link_cap.py#L84>
The parse function was used to train the RouteNet model. In this case we normalized the
data before we introduced it to RouteNet. It means that, once the model is trained, we
need to denormalize the output delay values of RouteNet to obtain the actual delay
predictions. Then, in our demo notebook
(https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
<https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/demo_notebooks/demo.ipynb>)
we loaded a model already trained. Note that to make predictions with RouteNet, the
training delay labels (features['delay']) are not needed anymore. However, in this
demo we wanted to compare the predictions made by RouteNet (after denormalization) with
the values produced by our simulator in a separate dataset that wasn't used for the
training. Then, we retrieve the actual delay values of the simulator
(features['delay']) without denormalization. Also, since we normalized the output
labels of RouteNet during training (in the function parse in
"routenet_with_link_cap.py"), we need to apply the reverse function to
denormalize the delays:
Training ("demo-routenet/code/routenet_with_link_cap.py"):
parse function:
if k == 'delay':
features[k] = (features[k] - 0.37) / 0.54 --> Delay labels
normalized used to train RouteNet
Evaluation ("demo-routenet/demo_notebooks/demo.ipynb"):
pred_Delay, label_Delay = sess.run([predictions, label])
"label" --> Real values produced by the simulator (label = features[target]
= features['delay'])
predictions = 0.54*preds + 0.37 --> Denormalization applied to RouteNet predictions
during the evaluation phase to obtain the real delay values predicted. Note that this is
the reverse function of the one applied in the training (function parse in
"demo-routenet/code/routenet_with_link_cap.py").
I hope this will clarify all your doubts.
Regards,
José
El 6/10/19 a las 09:55, Nathan Sowatskey escribió:
> Thank you José.
>
> I am trying to make sense of this, so I appreciate you bearing with me. The
normalisation seems to be fundamental to how RouteNet is used, but also seems not to be
discussed anywhere, so I just have the clues in the code to work with.
>
> In my experiments, I have performed the training with the delay input normalised, and
not normalised.
>
> Predictions with Delay Normalised as an Input Variable
> -------------------------------------------------------------------------
>
> If I normalise the delay input value, and (de)normalise the predictions, I get
results like this (this is with a checkpoint 51211).
>
> <Screenshot 2019-10-06 at 09.24.50.png>
>
> <Screenshot 2019-10-06 at 09.27.59.png>
>
> Looking at these results, one could draw the conclusion that the end-to-end process
is working as expected. What is not explained, though, is the reasoning behind the
normalisation.
>
> You do say in your response below, though, that “it is not necessary to normalise the
output parameters (i.e., delay) since we are not using them for training”, which seems
perfectly sensible. Given this, common sense, point, I don’t understand why the
delay is normalised in the parse function here:
>
>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
<https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/code/routenet_with_link_cap.py#L84>
>
> That parse function is used when reading the TF records data and passing it to the
model during training. So, transforming the delay value at that point doesn’t make sense
given that we are not using it for prediction.
>
> Since the demo notebook does also (de)normalise the predictions, it seems as though
the trained model in the supplied checkpoint 260380 actually was trained with the delay
value normalised, and so it had to be (de)normalised in the notebook, which is the result
I have reproduced here.
>
> There is no explicit rationale provided for normalising the target variable, or the
other input variables, though. If this is required here, then it might be for scaling
purposes. If that is the case, then I would suppose that there is some analysis that you
have done to determine the appropriate scaling factors. If that analysis does exist, it
might have been published somewhere I have not found yet.
>
> What might, also, make sense is if the delay is normalised when the code is being
used with jitter as the prediction target, but the code seems to be all about delay at
this stage.
>
> As I note above, since the normalisation appears not to be discussed anywhere, I only
have the clues in the code to go on.
>
> Predictions without Delay Normalised as an Input Variable
> -----------------------------------------------------------------------------
>
> For comparison, I have also trained without the delay value normalised, but with the
traffic and link_capacity normalised, as below in the parse function:
>
> if feature == 'traffic':
> features[feature] = (features[feature] - 0.17) / 0.13
> if feature == 'link_capacity':
> features[feature] = (features[feature] - 25.0) / 40.0
>
> I also do not normalise the predictions, and I get results like this from a
checkpoint 5904 (which is to say an early stage in the training):
>
>
> <Screenshot 2019-10-06 at 07.59.12.png>
>
>
>
> <Screenshot 2019-10-06 at 07.59.22.png>
>
> Given these results, it looks like the model I am training, without normalising delay
either as an input variable, or denormalising the delay predictions, is providing
reasonable predictions (given that it has only been trained for a relatively small number
of training steps).
>
> Conclusion
> ---------------
>
> A possible conclusion is simply that I have broken something in the way in which I
have refactored your original code. You will see, though, that I have been careful to also
write extensive unit and smoke tests, so I have confidence that my refactoring has not
changed the original functions of the code.
>
> My code, though, seems to produce reasonable predictions for delay without
normalisation of the delay. Of course, I am still using your original normalisation for
the traffic and link capacity, without understanding why yet.
>
> What are your thoughts please? Has the normalisation that you are employing been
discussed anywhere?
>
> Many thanks
>
> Nathan
>
>
>
>
>> On 30 Sep 2019, at 12:13, José Suárez-Varela <jsuarezv(a)ac.upc.edu
<mailto:jsuarezv@ac.upc.edu>> wrote:
>>
>>
>> Hi Nathan,
>>
>> The code in the demo notebook is used only for delay inference, not for training.
In this code, we load a model that we trained using the RouteNet implementation in
"routenet_with_link_cap.py". Then, we load samples from our datasets (generated
with our packet-level simulator), make the inference with the RouteNet model and finally
compare RouteNet's predictions with the values of our ground truth.
>>
>> In this case it is not necessary to normalize the output parameters (i.e., delay)
since we are not using them for training. We only normalize the input parameters of
RouteNet (traffic and link capacities). Note that we then denormalize RouteNet's
predictions to compare them with the real (denormalized) delay values of the ground truth
(variable "label_Delay"):
>>
>> predictions = 0.54*preds + 0.37
>>
>>
>>
>> Regards,
>>
>> José
>>
>> El 28/09/19 a las 17:28, Nathan Sowatskey escribió:
>>> Hi
>>>
>>> I have noted that the normalisation applied in the demo notebook here:
>>>
>>>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
<https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/demo_notebooks/demo.ipynb>
>>>
>>> Does not apply the same normalisation as the code here:
>>>
>>>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
<https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/code/routenet_with_link_cap.py#L85>
>>>
>>> Specifically, delay is not normalised in the demo notebook.
>>>
>>> The demo notebook loads a checkpoint from here:
>>>
>>>
https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/tra…
<https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/trained_models>
>>>
>>> This model, then, was created without normalising the delay also. That
implies that the code that was used to train that model is not the same code that is in
the routenet_with_link_cap.py code at the link above.
>>>
>>> In simpler terms, the demo notebook prediction does not work if the delay is
normalised as at routenet_with_link_cap.py#L85. So, the code for training given in this
repository is not compatible with the demo notebook and the trained model used as an
example.
>>>
>>> Regards
>>>
>>> Nathan
>>>
>>>
>>> _______________________________________________
>>> Kdn-users mailing list
>>>
>>> Kdn-users(a)knowledgedefinednetworking.org
<mailto:Kdn-users@knowledgedefinednetworking.org>
>>> https://mail.n3cat.upc.edu/cgi-bin/mailman/listinfo/kdn-users
<https://mail.n3cat.upc.edu/cgi-bin/mailman/listinfo/kdn-users>
10:13 a.m.
Yes, we used the same normalization function for traffic and link
capacities.
Ideally, you should compute the mean and standard deviation over all the
samples in your training dataset. However, using approximate values from
a subset of samples randomly selected will also help optimize the
training process.
Regards,
José
El 9/10/19 a las 06:52, Nathan Sowatskey escribió:
Many thanks.
I presume that the [(x - mean)/std. dev] is also the basis of the
normalisation for traffic and link_capacity, is that right?
In general, I should be introducing a function that carries out this
same normalisation analysis for any given data set, as the actual
values for mean and standard deviation will differ from one training
data set to another for different domains.
Presumably, also, you will have been thinking about being able to
label a given trained model with the characteristics of the data it
has been trained with, such that, given a range of trained models, you
could choose the appropriate trained model given the characteristics
of the data you are predicting from.
I imagine (and I can test later), that the OMNet++ generated data sets
that you used originally all have similar characteristics.
Regards
Nathan
On 8 Oct 2019, at 16:54, José Suárez-Varela
<jsuarezv(a)ac.upc.edu
<mailto:jsuarezv@ac.upc.edu>> wrote:
Hi Nathan,
Normalizing the input and output values is a well-known technique to
provide training stability to Deep Learning models in general.
Usually, if the input and output variables of the model follow a
normal distribution [N(0,1)], it is easier for deep learning models
to learn the data. This does not necessarily mean that the model
won't work if you don't normalize the data, but it often facilitates
the loss of the model to converge during training. You can see this
as an optimization technique. A common approach is just to measure
the mean and standard deviation on your training dataset (or a
representative subset) and normalize individually each variable by
applying a linear transformation [i.e., (x - mean)/std. dev.]. This
is what we did in the ACM SOSR paper. However, another approach that
we experimentally tried is to select the normalization function based
on the value distribution of each variable. Then, in the case of
RouteNet with nodes
(https://github.com/knowledgedefinednetworking/network-modeling-GNN/blob/mas…)
we analyzed the distribution of delays in our training dataset (not
public yet) and given that the distribution had a lot of density for
low values and a long tail for large values we thought that using a
logarithmic function to normalize could be more beneficial (and it
was eventually) to make the delay distribution seen by RouteNet
closer to a normal distribution.
Note that the parse function in our code reads the data from the
dataset (tfrecords). Then, when you normalize the delay labels
(features['delay']) it means that you take the delay values from the
ground truth (obtained by our packet-level simulator) and normalize
them. To train RouteNet we need supervised data (with labels), then
we normalize the labels from the ground truth (features['delay']) and
use them to train the model.
Once RouteNet is trained you can use it to produce predictions. In
this case the model is fed only by inputs (i.e., traffic, topology,
routing) and it produces an output value. If it was trained with
normalized output labels, it will produce normalized outputs and it
is necessary to apply denormalization to get the real values. In
principle, during evaluation you can ignore the delay values
(features['delay']) in the parse function given that they are the
labels used for training (i.e., the output of our simulator).
Regarding the code in the following link:
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
The parse function was used to train the RouteNet model. In this case
we normalized the data before we introduced it to RouteNet. It means
that, once the model is trained, we need to denormalize the output
delay values of RouteNet to obtain the actual delay predictions.
Then, in our demo notebook
(https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…)
we loaded a model already trained. Note that to make predictions with
RouteNet, the training delay labels (features['delay']) are not
needed anymore. However, in this demo we wanted to compare the
predictions made by RouteNet (after denormalization) with the values
produced by our simulator in a separate dataset that wasn't used for
the training. Then, we retrieve the actual delay values of the
simulator (features['delay']) without denormalization. Also, since we
normalized the output labels of RouteNet during training (in the
function parse in "routenet_with_link_cap.py"), we need to apply the
reverse function to denormalize the delays:
_Training_ ("demo-routenet/code/routenet_with_link_cap.py"):
parse function:
if k == 'delay':
features[k] = (features[k] - 0.37) / 0.54 -->
Delay labels normalized used to train RouteNet
_Evaluation_ ("demo-routenet/demo_notebooks/demo.ipynb"):
pred_Delay, label_Delay = sess.run([predictions, label])
"label" --> Real values produced by the simulator (label =
features[target] = features['delay'])
predictions = 0.54*preds + 0.37 --> Denormalization applied to
RouteNet predictions during the evaluation phase to obtain the real
delay values predicted. Note that this is the reverse function of the
one applied in the training (function parse in
"demo-routenet/code/routenet_with_link_cap.py").
I hope this will clarify all your doubts.
Regards,
José
El 6/10/19 a las 09:55, Nathan Sowatskey escribió:
> Thank you José.
>
> I am trying to make sense of this, so I appreciate you bearing with
> me. The normalisation seems to be fundamental to how RouteNet is
> used, but also seems not to be discussed anywhere, so I just have
> the clues in the code to work with.
>
> In my experiments, I have performed the training with the delay
> input normalised, and not normalised.
>
> Predictions with Delay Normalised as an Input Variable
> -------------------------------------------------------------------------
>
> If I normalise the delay input value, and (de)normalise the
> predictions, I get results like this (this is with a checkpoint 51211).
>
> <Screenshot 2019-10-06 at 09.24.50.png>
>
> <Screenshot 2019-10-06 at 09.27.59.png>
>
> Looking at these results, one could draw the conclusion that the
> end-to-end process is working as expected. What is not explained,
> though, is the reasoning behind the normalisation.
>
> You do say in your response below, though, that “it is not necessary
> to normalise the output parameters (i.e., delay) since we are not
> using them for training”, which seems perfectly sensible. Given
> this, common sense, point, I don’t understand why the delay is
> normalised in the parse function here:
>
>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
>
> That parse function is used when reading the TF records data and
> passing it to the model during training. So, transforming the delay
> value at that point doesn’t make sense given that we are not using
> it for prediction.
>
> Since the demo notebook does also (de)normalise the predictions, it
> seems as though the trained model in the supplied checkpoint 260380
> actually was trained with the delay value normalised, and so it had
> to be (de)normalised in the notebook, which is the result I have
> reproduced here.
>
> There is no explicit rationale provided for normalising the target
> variable, or the other input variables, though. If this is required
> here, then it might be for scaling purposes. If that is the case,
> then I would suppose that there is some analysis that you have done
> to determine the appropriate scaling factors. If that analysis does
> exist, it might have been published somewhere I have not found yet.
>
> What might, also, make sense is if the delay is normalised when the
> code is being used with jitter as the prediction target, but the
> code seems to be all about delay at this stage.
>
> As I note above, since the normalisation appears not to be discussed
> anywhere, I only have the clues in the code to go on.
>
> Predictions without Delay Normalised as an Input Variable
> -----------------------------------------------------------------------------
>
> For comparison, I have also trained without the delay value
> normalised, but with the traffic and link_capacity normalised, as
> below in the parse function:
>
> if feature == 'traffic':
> features[feature] = (features[feature] - 0.17) / 0.13
> if feature == 'link_capacity':
> features[feature] = (features[feature] - 25.0) / 40.0
>
> I also do not normalise the predictions, and I get results like this
> from a checkpoint 5904 (which is to say an early stage in the training):
>
>
> <Screenshot 2019-10-06 at 07.59.12.png>
>
>
>
> <Screenshot 2019-10-06 at 07.59.22.png>
>
> Given these results, it looks like the model I am training, without
> normalising delay either as an input variable, or denormalising the
> delay predictions, is providing reasonable predictions (given that
> it has only been trained for a relatively small number of training
> steps).
>
> Conclusion
> ---------------
>
> A possible conclusion is simply that I have broken something in the
> way in which I have refactored your original code. You will see,
> though, that I have been careful to also write extensive unit and
> smoke tests, so I have confidence that my refactoring has not
> changed the original functions of the code.
>
> My code, though, seems to produce reasonable predictions for delay
> without normalisation of the delay. Of course, I am still using your
> original normalisation for the traffic and link capacity, without
> understanding why yet.
>
> What are your thoughts please? Has the normalisation that you are
> employing been discussed anywhere?
>
> Many thanks
>
> Nathan
>
>
>
>
>> On 30 Sep 2019, at 12:13, José Suárez-Varela <jsuarezv(a)ac.upc.edu
>> <mailto:jsuarezv@ac.upc.edu>> wrote:
>>
>>
>> Hi Nathan,
>>
>> The code in the demo notebook is used only for delay inference, not
>> for training. In this code, we load a model that we trained using
>> the RouteNet implementation in
>> "routenet_with_link_cap.py". Then, we load samples from our
>> datasets (generated with our packet-level simulator), make the
>> inference with the RouteNet model and finally compare RouteNet's
>> predictions with the values of our ground truth.
>>
>> In this case it is not necessary to normalize the output parameters
>> (i.e., delay) since we are not using them for training. We only
>> normalize the input parameters of RouteNet (traffic and link
>> capacities). Note that we then denormalize RouteNet's predictions
>> to compare them with the real (denormalized) delay values of the
>> ground truth (variable "label_Delay"):
>>
>> predictions = 0.54*preds + 0.37
>>
>>
>>
>> Regards,
>>
>> José
>>
>> El 28/09/19 a las 17:28, Nathan Sowatskey escribió:
>>> Hi
>>>
>>> I have noted that the normalisation applied in the demo notebook here:
>>>
>>>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/dem…
>>>
>>> Does not apply the same normalisation as the code here:
>>>
>>>
https://github.com/knowledgedefinednetworking/demo-routenet/blob/master/cod…
>>>
>>> Specifically, delay is not normalised in the demo notebook.
>>>
>>> The demo notebook loads a checkpoint from here:
>>>
>>>
https://github.com/knowledgedefinednetworking/demo-routenet/tree/master/tra…
>>>
>>> This model, then, was created without normalising the delay also.
>>> That implies that the code that was used to train that model is
>>> not the same code that is in the routenet_with_link_cap.py code at
>>> the link above.
>>>
>>> In simpler terms, the demo notebook prediction does not work if
>>> the delay is normalised as at routenet_with_link_cap.py#L85. So,
>>> the code for training given in this repository is not compatible
>>> with the demo notebook and the trained model used as an example.
>>>
>>> Regards
>>>
>>> Nathan
>>>
>>>
>>> _______________________________________________
>>> Kdn-users mailing list
>>>
>>> Kdn-users(a)knowledgedefinednetworking.org
>>> https://mail.n3cat.upc.edu/cgi-bin/mailman/listinfo/kdn-users
2190
days inactive
2201
days old
kdn-users@knowledgedefinednetworking.org
5 comments
2 participants
participants (2)
-
 José Suárez-Varela
José Suárez-Varela -
 Nathan Sowatskey
Nathan Sowatskey